Chapter 7 Novelty search
Results for the novelty search parameter sweep on the diagnostics with no valleys.
7.1 Data setup
over_time_df <- read.csv(paste(DATA_DIR,'OVER-TIME/nov.csv', sep = "", collapse = NULL), header = TRUE, stringsAsFactors = FALSE)
over_time_df$uni_str_pos = over_time_df$uni_str_pos + over_time_df$arc_acti_gene - over_time_df$overlap
over_time_df$K <- factor(over_time_df$K, levels = NS_LIST)
best_df <- read.csv(paste(DATA_DIR,'BEST/nov.csv', sep = "", collapse = NULL), header = TRUE, stringsAsFactors = FALSE)
best_df$K <- factor(best_df$K, levels = NS_LIST)7.2 Exploitation rate results
Here we present the results for best performances found by each selection scheme parameter on the exploitation rate diagnostic. 50 replicates are conducted for each scheme explored.
7.2.1 Performance over time
Best performance in a population over time. Data points on the graph is the average performance across 50 replicates every 2000 generations. Shading comes from the best and worse performance across 50 replicates.
lines = filter(over_time_df, acro == 'exp') %>%
group_by(K, gen) %>%
dplyr::summarise(
min = min(pop_fit_max) / DIMENSIONALITY,
mean = mean(pop_fit_max) / DIMENSIONALITY,
max = max(pop_fit_max) / DIMENSIONALITY
)## `summarise()` has grouped output by 'K'. You can override using the `.groups`
## argument.over_time_plot = ggplot(lines, aes(x=gen, y=mean, group = K, fill = K, color = K, shape = K)) +
geom_ribbon(aes(ymin = min, ymax = max), alpha = 0.1) +
geom_line(size = 0.5) +
geom_point(data = filter(lines, gen %% 2000 == 0 & gen != 0), size = 1.5, stroke = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Average trait score"
) +
scale_x_continuous(
name="Generations",
limits=c(0, 50000),
breaks=c(0, 10000, 20000, 30000, 40000, 50000),
labels=c("0e+4", "1e+4", "2e+4", "3e+4", "4e+4", "5e+4")
) +
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette) +
scale_fill_manual(values = cb_palette) +
ggtitle('Performance over time')+
p_theme +
guides(
shape=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
color=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
fill=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors')
)
over_time_plot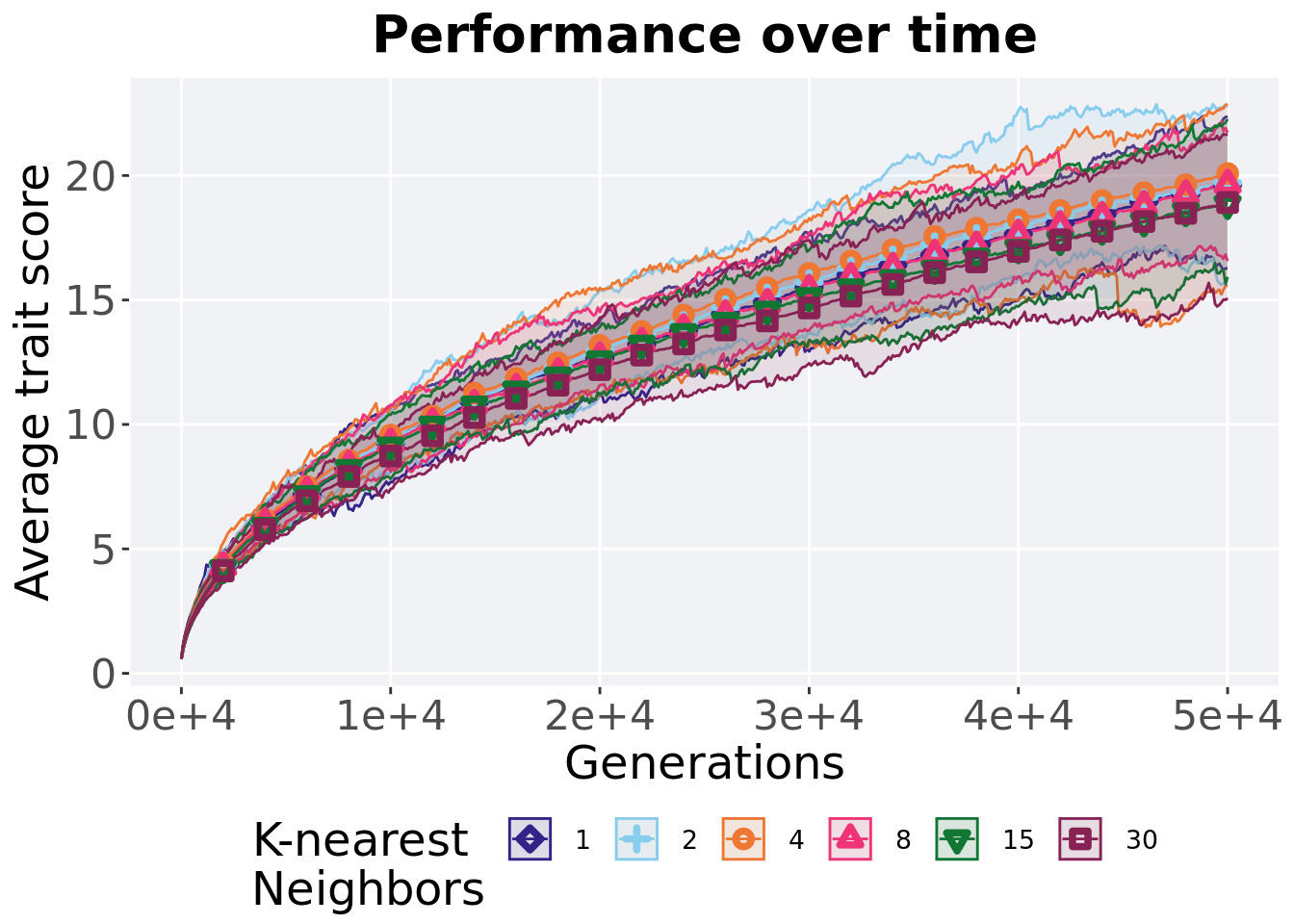
7.2.2 Best performance throughout
Best performance reached throughout 50,000 generations in a population.
plot = filter(best_df, var == 'pop_fit_max' & acro == 'exp') %>%
ggplot(., aes(x = K, y = val / DIMENSIONALITY, color = K, fill = K, shape = K)) +
geom_flat_violin(position = position_nudge(x = .1, y = 0), scale = 'width', alpha = 0.2, width = 1.5) +
geom_boxplot(color = 'black', width = .07, outlier.shape = NA, alpha = 0.0, size = 1.0, position = position_nudge(x = .16, y = 0)) +
geom_point(position = position_jitter(width = 0.03, height = 0.02), size = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Average trait score",
limits = c(10,40)
) +
scale_x_discrete(
name="K"
)+
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette, ) +
scale_fill_manual(values = cb_palette) +
ggtitle('Best performance throughout')+
p_theme + theme(legend.title=element_blank())
plot_grid(
plot +
theme(legend.position="none"),
legend,
nrow=2,
rel_heights = c(3,1)
)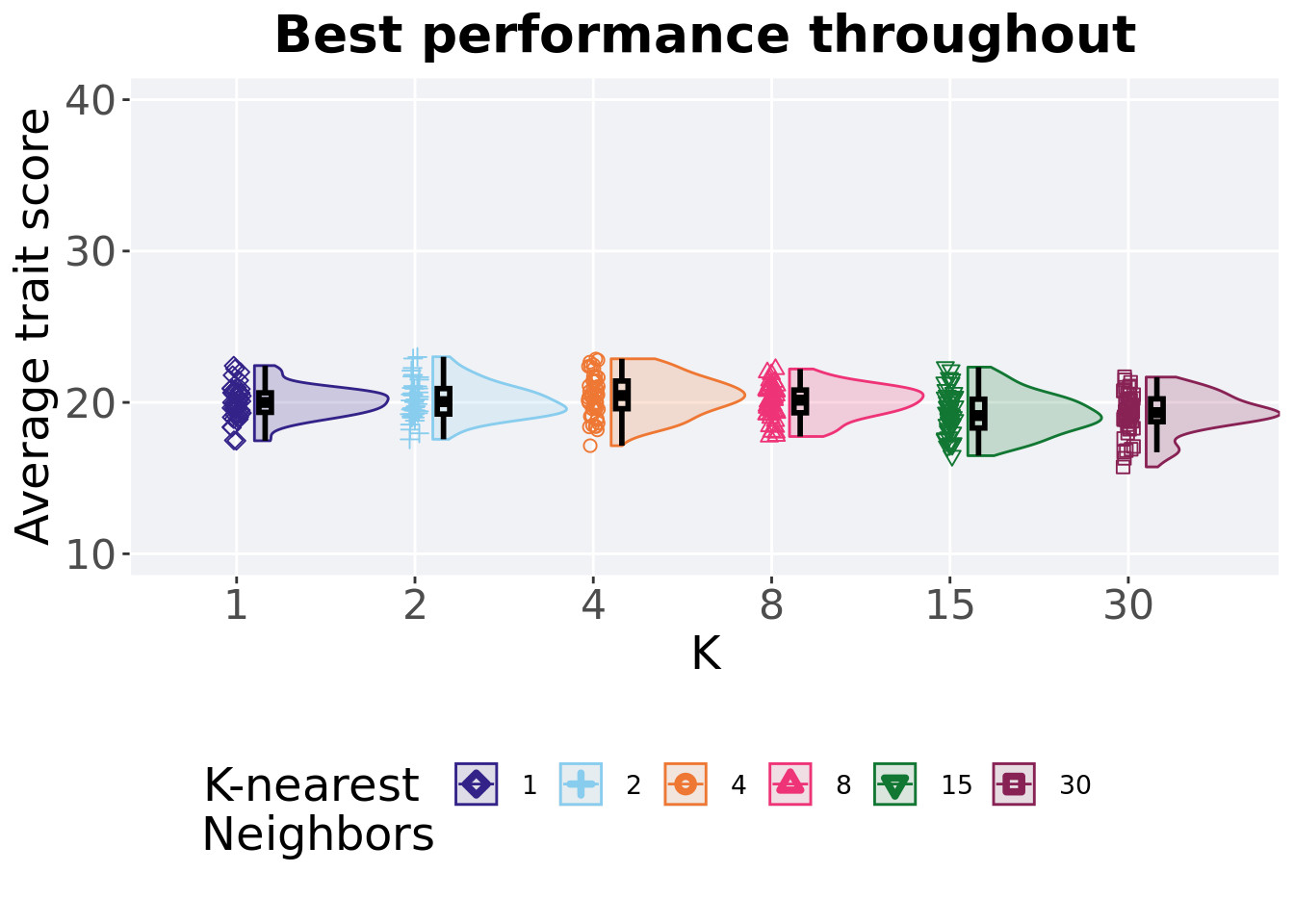
7.2.2.1 Stats
Summary statistics for the best performance.
performance = filter(best_df, var == 'pop_fit_max' & acro == 'exp')
performance$K = factor(performance$K, levels = c('1','2','4','8','30','15'))
performance %>%
group_by(K) %>%
dplyr::summarise(
count = n(),
na_cnt = sum(is.na(val)),
min = min(val / DIMENSIONALITY, na.rm = TRUE),
median = median(val / DIMENSIONALITY, na.rm = TRUE),
mean = mean(val / DIMENSIONALITY, na.rm = TRUE),
max = max(val / DIMENSIONALITY, na.rm = TRUE),
IQR = IQR(val / DIMENSIONALITY, na.rm = TRUE)
)## # A tibble: 6 x 8
## K count na_cnt min median mean max IQR
## <fct> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 50 0 17.5 20.0 20.0 22.4 1.29
## 2 2 50 0 17.6 20.1 20.1 23.0 1.68
## 3 4 50 0 17.1 20.5 20.4 22.9 1.83
## 4 8 50 0 17.7 20.1 20.0 22.2 1.50
## 5 30 50 0 15.7 19.3 19.3 21.7 1.51
## 6 15 50 0 16.5 19.1 19.3 22.3 1.90Kruskal–Wallis test illustrates evidence of statistical differences.
##
## Kruskal-Wallis rank sum test
##
## data: val by K
## Kruskal-Wallis chi-squared = 28.774, df = 5, p-value = 2.568e-05Results for post-hoc Wilcoxon rank-sum test with a Bonferroni correction.
pairwise.wilcox.test(x = performance$val, g = performance$K, p.adjust.method = "bonferroni",
paired = FALSE, conf.int = FALSE, alternative = 't')##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: performance$val and performance$K
##
## 1 2 4 8 30
## 2 1.0000 - - - -
## 4 1.0000 1.0000 - - -
## 8 1.0000 1.0000 1.0000 - -
## 30 0.0829 0.0794 0.0032 0.0940 -
## 15 0.0359 0.0259 0.0018 0.0440 1.0000
##
## P value adjustment method: bonferroni7.3 Ordered exploitation results
Here we present the results for best performances found by each selection scheme parameter on the exploitation rate diagnostic. 50 replicates are conducted for each scheme explored.
7.3.1 Performance over time
Best performance in a population over time. Data points on the graph is the average performance across 50 replicates every 2000 generations. Shading comes from the best and worse performance across 50 replicates.
lines = filter(over_time_df, acro == 'ord') %>%
group_by(K, gen) %>%
dplyr::summarise(
min = min(pop_fit_max) / DIMENSIONALITY,
mean = mean(pop_fit_max) / DIMENSIONALITY,
max = max(pop_fit_max) / DIMENSIONALITY
)## `summarise()` has grouped output by 'K'. You can override using the `.groups`
## argument.ggplot(lines, aes(x=gen, y=mean, group = K, fill = K, color = K, shape = K)) +
geom_ribbon(aes(ymin = min, ymax = max), alpha = 0.1) +
geom_line(size = 0.5) +
geom_point(data = filter(lines, gen %% 2000 == 0 & gen != 0), size = 1.5, stroke = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Average trait score"
) +
scale_x_continuous(
name="Generations",
limits=c(0, 50000),
breaks=c(0, 10000, 20000, 30000, 40000, 50000),
labels=c("0e+4", "1e+4", "2e+4", "3e+4", "4e+4", "5e+4")
) +
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette) +
scale_fill_manual(values = cb_palette) +
ggtitle('Performance over time')+
p_theme +
guides(
shape=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
color=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
fill=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors')
)
7.3.2 Best performance throughout
Best performance reached throughout 50,000 generations in a population.
plot = filter(best_df, var == 'pop_fit_max' & acro == 'ord') %>%
ggplot(., aes(x = K, y = val / DIMENSIONALITY, color = K, fill = K, shape = K)) +
geom_flat_violin(position = position_nudge(x = .1, y = 0), scale = 'width', alpha = 0.2, width = 1.5) +
geom_boxplot(color = 'black', width = .07, outlier.shape = NA, alpha = 0.0, size = 1.0, position = position_nudge(x = .16, y = 0)) +
geom_point(position = position_jitter(width = 0.03, height = 0.02), size = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Average trait score",
limits = c(0,10)
) +
scale_x_discrete(
name="K"
)+
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette, ) +
scale_fill_manual(values = cb_palette) +
ggtitle('Best performance throughout')+
p_theme + theme(legend.title=element_blank())
plot_grid(
plot +
theme(legend.position="none"),
legend,
nrow=2,
rel_heights = c(3,1)
)
7.3.2.1 Stats
Summary statistics for the best performance.
performance = filter(best_df, var == 'pop_fit_max' & acro == 'ord')
performance$K = factor(performance$K, levels = c('1','2','4','8','15','30'))
performance %>%
group_by(K) %>%
dplyr::summarise(
count = n(),
na_cnt = sum(is.na(val)),
min = min(val / DIMENSIONALITY, na.rm = TRUE),
median = median(val / DIMENSIONALITY, na.rm = TRUE),
mean = mean(val / DIMENSIONALITY, na.rm = TRUE),
max = max(val / DIMENSIONALITY, na.rm = TRUE),
IQR = IQR(val / DIMENSIONALITY, na.rm = TRUE)
)## # A tibble: 6 x 8
## K count na_cnt min median mean max IQR
## <fct> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 50 0 2.44 4.13 4.09 6.06 0.873
## 2 2 50 0 3.19 4.85 4.90 6.24 0.832
## 3 4 50 0 3.66 5.07 5.16 6.55 1.00
## 4 8 50 0 3.13 4.71 4.64 6.42 1.08
## 5 15 50 0 2.11 3.72 3.82 5.64 0.710
## 6 30 50 0 2.98 4.78 4.81 6.36 1.03Kruskal–Wallis test illustrates evidence of statistical differences.
##
## Kruskal-Wallis rank sum test
##
## data: val by K
## Kruskal-Wallis chi-squared = 91.122, df = 5, p-value < 2.2e-16Results for post-hoc Wilcoxon rank-sum test with a Bonferroni correction.
pairwise.wilcox.test(x = performance$val, g = performance$K, p.adjust.method = "bonferroni",
paired = FALSE, conf.int = FALSE, alternative = 't')##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: performance$val and performance$K
##
## 1 2 4 8 15
## 2 1.4e-05 - - - -
## 4 1.1e-08 1.00000 - - -
## 8 0.00600 1.00000 0.01687 - -
## 15 0.61428 3.3e-09 1.0e-11 6.4e-06 -
## 30 0.00011 1.00000 0.31667 1.00000 8.7e-08
##
## P value adjustment method: bonferroni7.4 Contradictory objectives results
Here we present the results for activation gene coverage and satisfactory trait coverage found by each selection scheme parameter on the contradictory objectives diagnostic. 50 replicates are conducted for each scheme parameters explored.
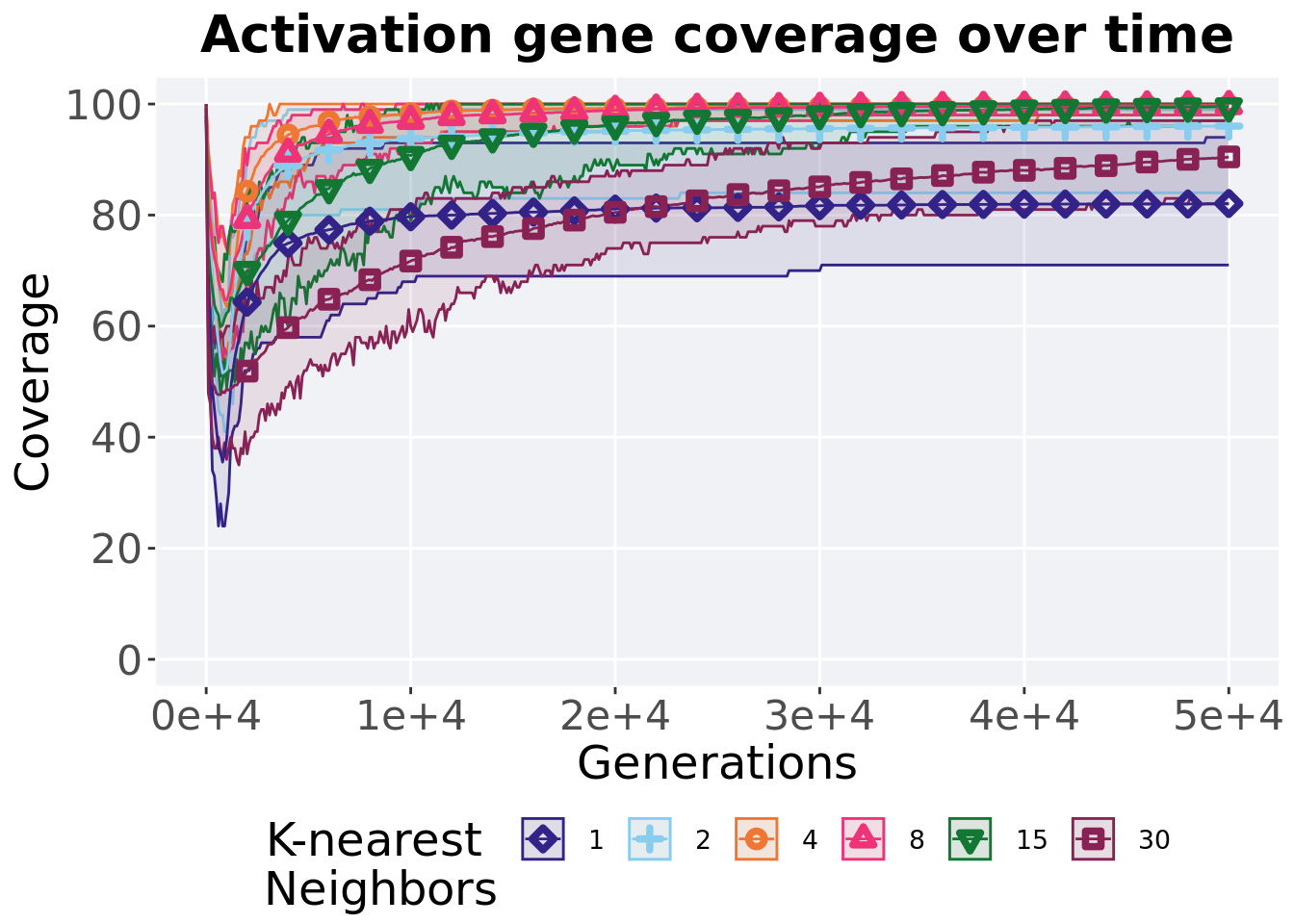
7.4.1 Activation gene coverage over time
Activation gene coverage in a population over time. Data points on the graph is the average activation gene coverage across 50 replicates every 2000 generations. Shading comes from the best and worse coverage across 50 replicates.
lines = filter(over_time_df, acro == 'con') %>%
group_by(K, gen) %>%
dplyr::summarise(
min = min(uni_str_pos),
mean = mean(uni_str_pos),
max = max(uni_str_pos)
)## `summarise()` has grouped output by 'K'. You can override using the `.groups`
## argument.ggplot(lines, aes(x=gen, y=mean, group = K, fill = K, color = K, shape = K)) +
geom_ribbon(aes(ymin = min, ymax = max), alpha = 0.1) +
geom_line(size = 0.5) +
geom_point(data = filter(lines, gen %% 2000 == 0 & gen != 0), size = 1.5, stroke = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Coverage",
limits=c(0, 100),
breaks=seq(0,100, 20),
labels=c("0", "20", "40", "60", "80", "100")
) +
scale_x_continuous(
name="Generations",
limits=c(0, 50000),
breaks=c(0, 10000, 20000, 30000, 40000, 50000),
labels=c("0e+4", "1e+4", "2e+4", "3e+4", "4e+4", "5e+4")
) +
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette) +
scale_fill_manual(values = cb_palette) +
ggtitle('Activation gene coverage over time')+
p_theme +
guides(
shape=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
color=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
fill=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors')
)
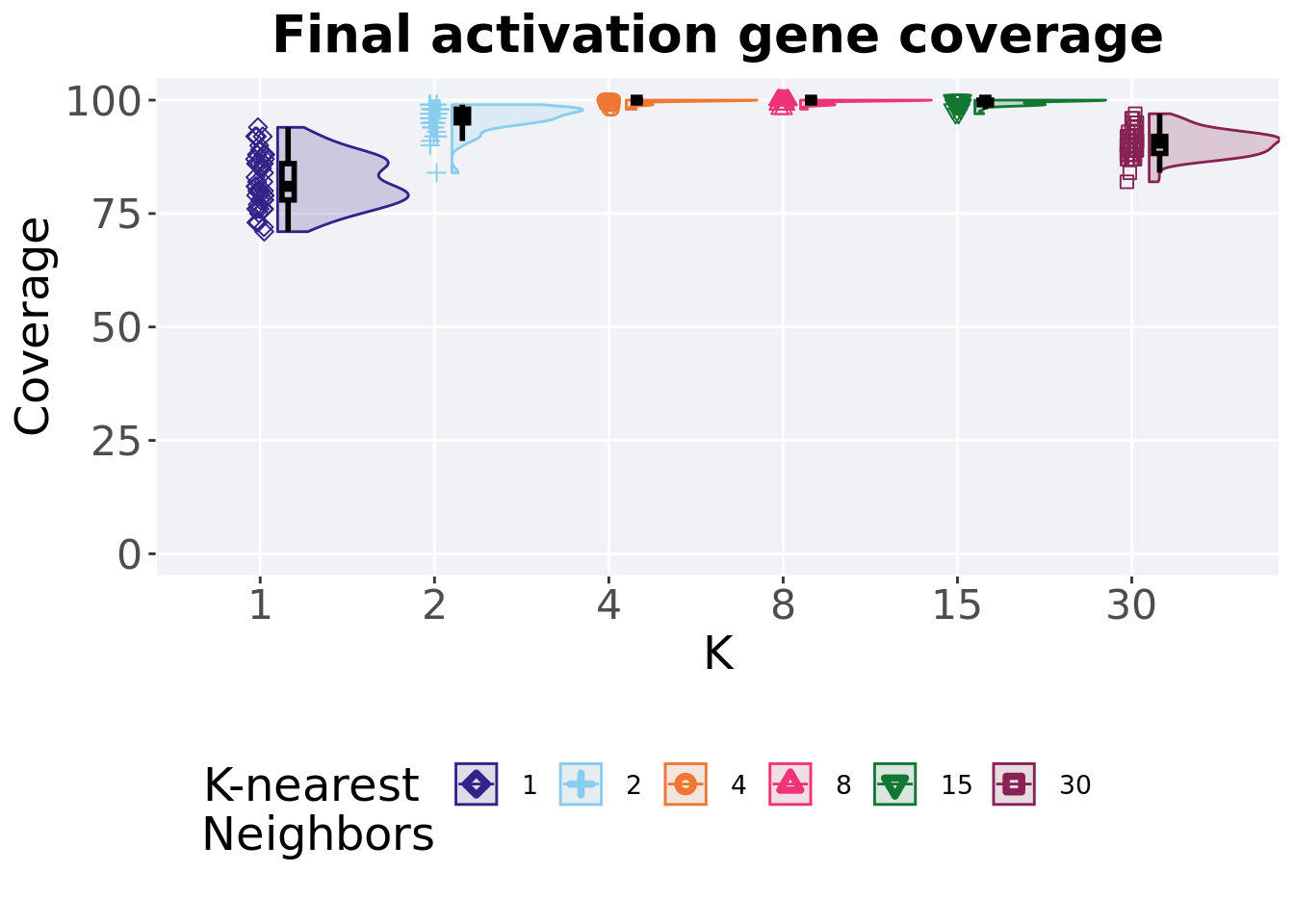
7.4.2 Final activation gene coverage
Activation gene coverage found in the final population at 50,000 generations.
plot = filter(over_time_df, gen == 50000 & acro == 'con') %>%
ggplot(., aes(x = K, y = uni_str_pos, color = K, fill = K, shape = K)) +
geom_flat_violin(position = position_nudge(x = .1, y = 0), scale = 'width', alpha = 0.2, width = 1.5) +
geom_boxplot(color = 'black', width = .07, outlier.shape = NA, alpha = 0.0, size = 1.0, position = position_nudge(x = .16, y = 0)) +
geom_point(position = position_jitter(width = 0.03, height = 0.02), size = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Coverage",
limits=c(0, 100.1)
) +
scale_x_discrete(
name="K"
)+
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette, ) +
scale_fill_manual(values = cb_palette) +
ggtitle('Final activation gene coverage')+
p_theme + theme(legend.title=element_blank())
plot_grid(
plot +
theme(legend.position="none"),
legend,
nrow=2,
rel_heights = c(3,1)
)
7.4.2.1 Stats
Summary statistics for the generation a satisfactory solution is found.
act_coverage = filter(over_time_df, gen == 50000 & acro == 'con')
act_coverage$K = factor(act_coverage$K, levels = NS_LIST)
act_coverage %>%
group_by(K) %>%
dplyr::summarise(
count = n(),
na_cnt = sum(is.na(uni_str_pos)),
min = min(uni_str_pos, na.rm = TRUE),
median = median(uni_str_pos, na.rm = TRUE),
mean = mean(uni_str_pos, na.rm = TRUE),
max = max(uni_str_pos, na.rm = TRUE),
IQR = IQR(uni_str_pos, na.rm = TRUE)
)## # A tibble: 6 x 8
## K count na_cnt min median mean max IQR
## <fct> <int> <int> <int> <dbl> <dbl> <int> <dbl>
## 1 1 50 0 71 81 82.1 94 8
## 2 2 50 0 84 96.5 96.0 99 3
## 3 4 50 0 98 100 99.7 100 0
## 4 8 50 0 98 100 99.7 100 0
## 5 15 50 0 97 100 99.5 100 1
## 6 30 50 0 82 90.5 90.5 97 3.75Kruskal–Wallis test illustrates evidence of statistical differences.
##
## Kruskal-Wallis rank sum test
##
## data: uni_str_pos by K
## Kruskal-Wallis chi-squared = 257.39, df = 5, p-value < 2.2e-16Results for post-hoc Wilcoxon rank-sum test with a Bonferroni correction.
pairwise.wilcox.test(x = act_coverage$uni_str_pos, g = act_coverage$K, p.adjust.method = "bonferroni",
paired = FALSE, conf.int = FALSE, alternative = 't')##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: act_coverage$uni_str_pos and act_coverage$K
##
## 1 2 4 8 15
## 2 9.0e-16 - - - -
## 4 < 2e-16 3.6e-16 - - -
## 8 < 2e-16 2.7e-16 1.00 - -
## 15 < 2e-16 2.4e-14 0.93 1.00 -
## 30 1.1e-10 1.3e-11 < 2e-16 < 2e-16 < 2e-16
##
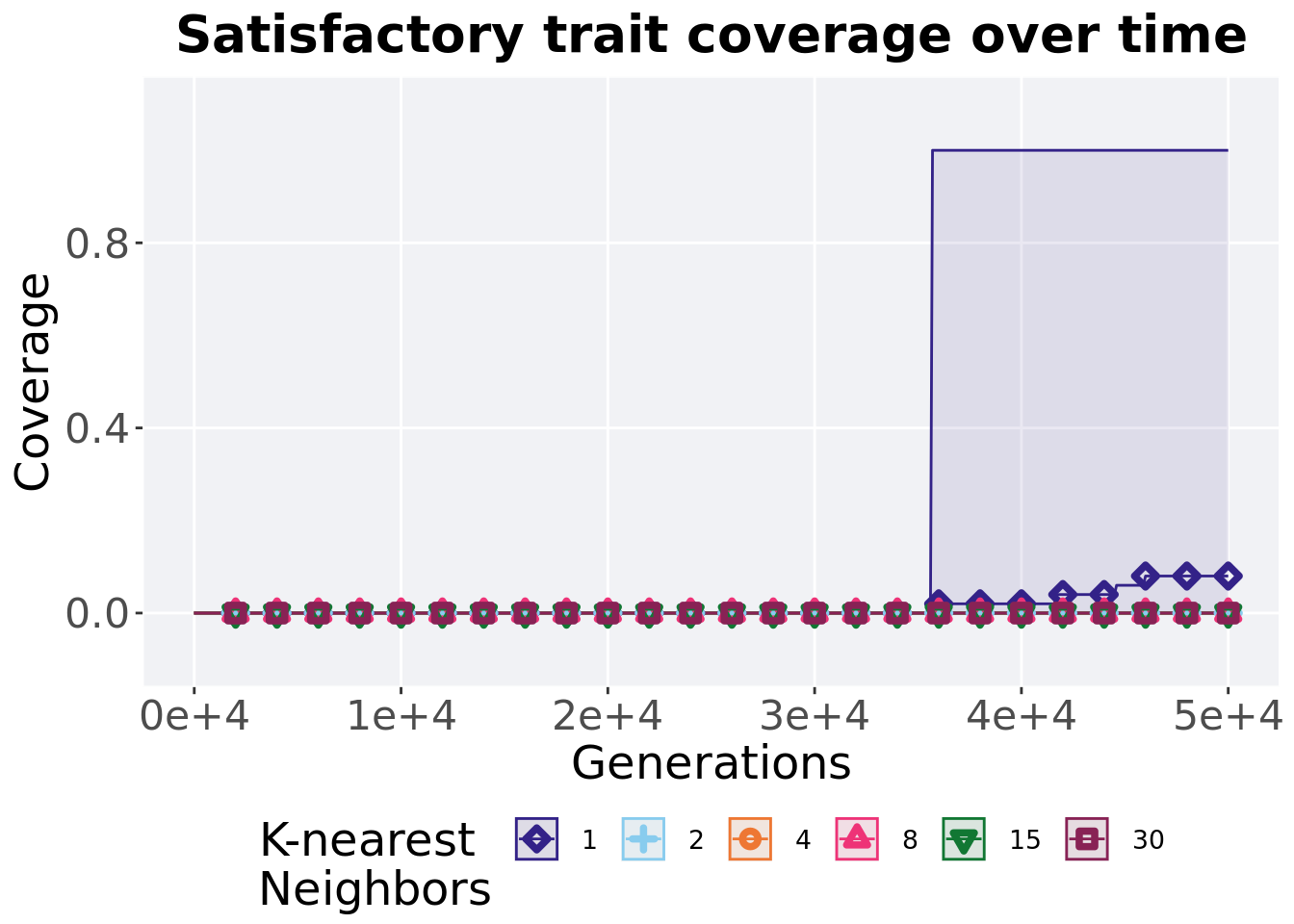
## P value adjustment method: bonferroni7.4.3 Satisfactory trait coverage over time
Satisfactory trait coverage in a population over time. Data points on the graph is the average activation gene coverage across 50 replicates every 2000 generations. Shading comes from the best and worse coverage across 50 replicates.
lines = filter(over_time_df, acro == 'con') %>%
group_by(K, gen) %>%
dplyr::summarise(
min = min(pop_uni_obj),
mean = mean(pop_uni_obj),
max = max(pop_uni_obj)
)## `summarise()` has grouped output by 'K'. You can override using the `.groups`
## argument.ggplot(lines, aes(x=gen, y=mean, group = K, fill = K, color = K, shape = K)) +
geom_ribbon(aes(ymin = min, ymax = max), alpha = 0.1) +
geom_line(size = 0.5) +
geom_point(data = filter(lines, gen %% 2000 == 0 & gen != 0), size = 1.5, stroke = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Coverage",
limits=c(-0.1, 1.1)
) +
scale_x_continuous(
name="Generations",
limits=c(0, 50000),
breaks=c(0, 10000, 20000, 30000, 40000, 50000),
labels=c("0e+4", "1e+4", "2e+4", "3e+4", "4e+4", "5e+4")
) +
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette) +
scale_fill_manual(values = cb_palette) +
ggtitle('Satisfactory trait coverage over time')+
p_theme +
guides(
shape=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
color=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
fill=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors')
)
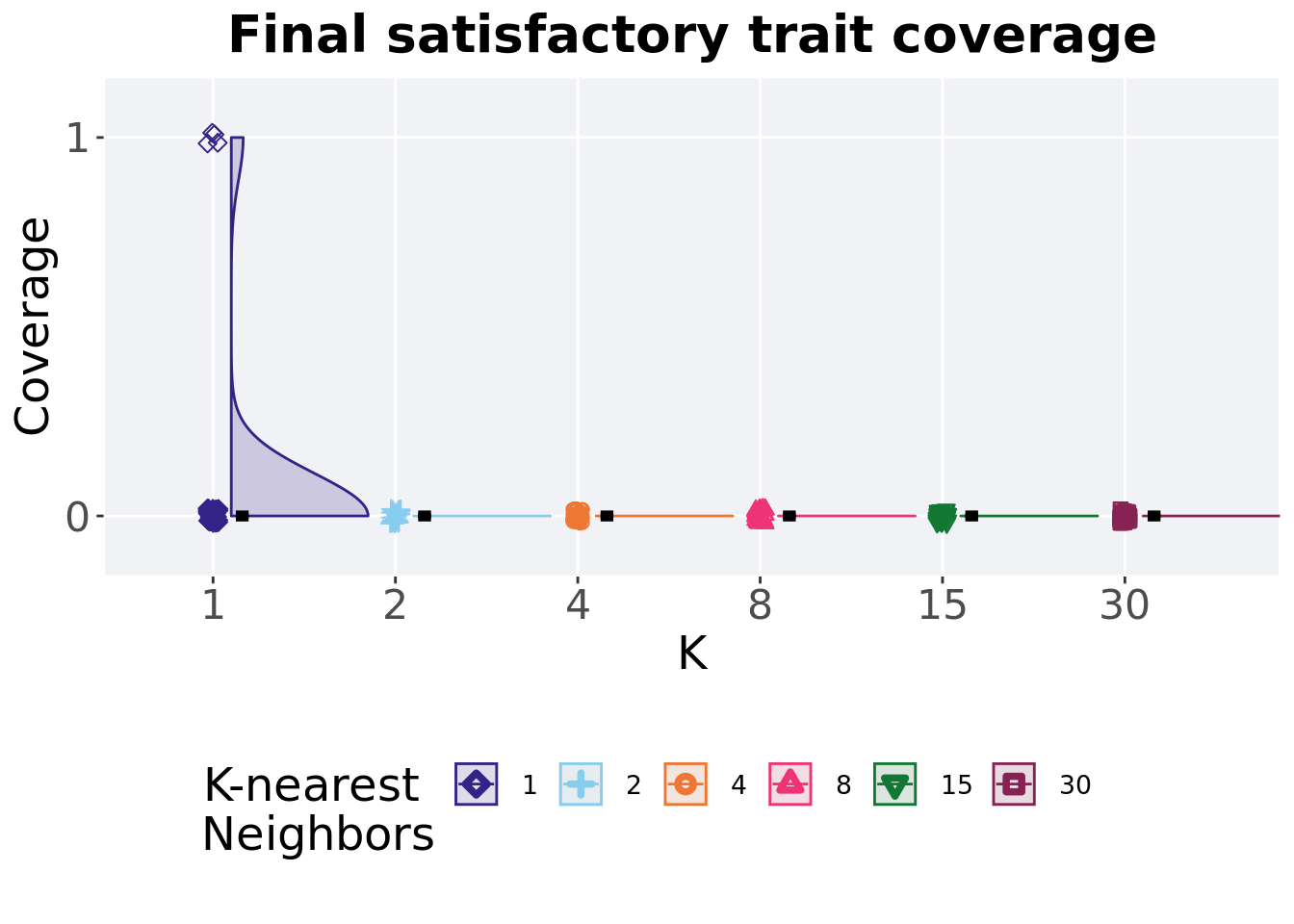
7.4.4 Final satisfactory trait coverage
Satisfactory trait coverage found in the final population at 50,000 generations.
plot = filter(over_time_df, gen == 50000 & acro == 'con') %>%
ggplot(., aes(x = K, y = pop_uni_obj, color = K, fill = K, shape = K)) +
geom_flat_violin(position = position_nudge(x = .1, y = 0), scale = 'width', alpha = 0.2, width = 1.5) +
geom_boxplot(color = 'black', width = .07, outlier.shape = NA, alpha = 0.0, size = 1.0, position = position_nudge(x = .16, y = 0)) +
geom_point(position = position_jitter(width = 0.03, height = 0.02), size = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Coverage",
limits=c(-0.1, 1.1),
breaks = c(0,1)
) +
scale_x_discrete(
name="K"
)+
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette, ) +
scale_fill_manual(values = cb_palette) +
ggtitle('Final satisfactory trait coverage')+
p_theme + theme(legend.title=element_blank())
plot_grid(
plot +
theme(legend.position="none"),
legend,
nrow=2,
rel_heights = c(3,1)
)
7.4.4.1 Stats
Summary statistics for the generation a satisfactory solution is found.
sat_coverage = filter(over_time_df, gen == 50000 & acro == 'con')
sat_coverage$K = factor(sat_coverage$K, levels = NS_LIST)
sat_coverage %>%
group_by(K) %>%
dplyr::summarise(
count = n(),
na_cnt = sum(is.na(pop_uni_obj)),
min = min(pop_uni_obj, na.rm = TRUE),
median = median(pop_uni_obj, na.rm = TRUE),
mean = mean(pop_uni_obj, na.rm = TRUE),
max = max(pop_uni_obj, na.rm = TRUE),
IQR = IQR(pop_uni_obj, na.rm = TRUE)
)## # A tibble: 6 x 8
## K count na_cnt min median mean max IQR
## <fct> <int> <int> <int> <dbl> <dbl> <int> <dbl>
## 1 1 50 0 0 0 0.08 1 0
## 2 2 50 0 0 0 0 0 0
## 3 4 50 0 0 0 0 0 0
## 4 8 50 0 0 0 0 0 0
## 5 15 50 0 0 0 0 0 0
## 6 30 50 0 0 0 0 0 0Kruskal–Wallis test illustrates evidence of statistical differences.
##
## Kruskal-Wallis rank sum test
##
## data: pop_uni_obj by K
## Kruskal-Wallis chi-squared = 20.203, df = 5, p-value = 0.001145Results for post-hoc Wilcoxon rank-sum test with a Bonferroni correction.
pairwise.wilcox.test(x = sat_coverage$pop_uni_obj, g = sat_coverage$K, p.adjust.method = "bonferroni",
paired = FALSE, conf.int = FALSE, alternative = 't')##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: sat_coverage$pop_uni_obj and sat_coverage$K
##
## 1 2 4 8 15
## 2 0.22 - - - -
## 4 0.22 - - - -
## 8 0.22 - - - -
## 15 0.22 - - - -
## 30 0.22 - - - -
##
## P value adjustment method: bonferroni7.5 Multi-path exploration results
Here we present the results for best performances and activation gene coverage found by each selection scheme parameter on the multi-path exploration diagnostic. 50 replicates are conducted for each scheme parameter explored.
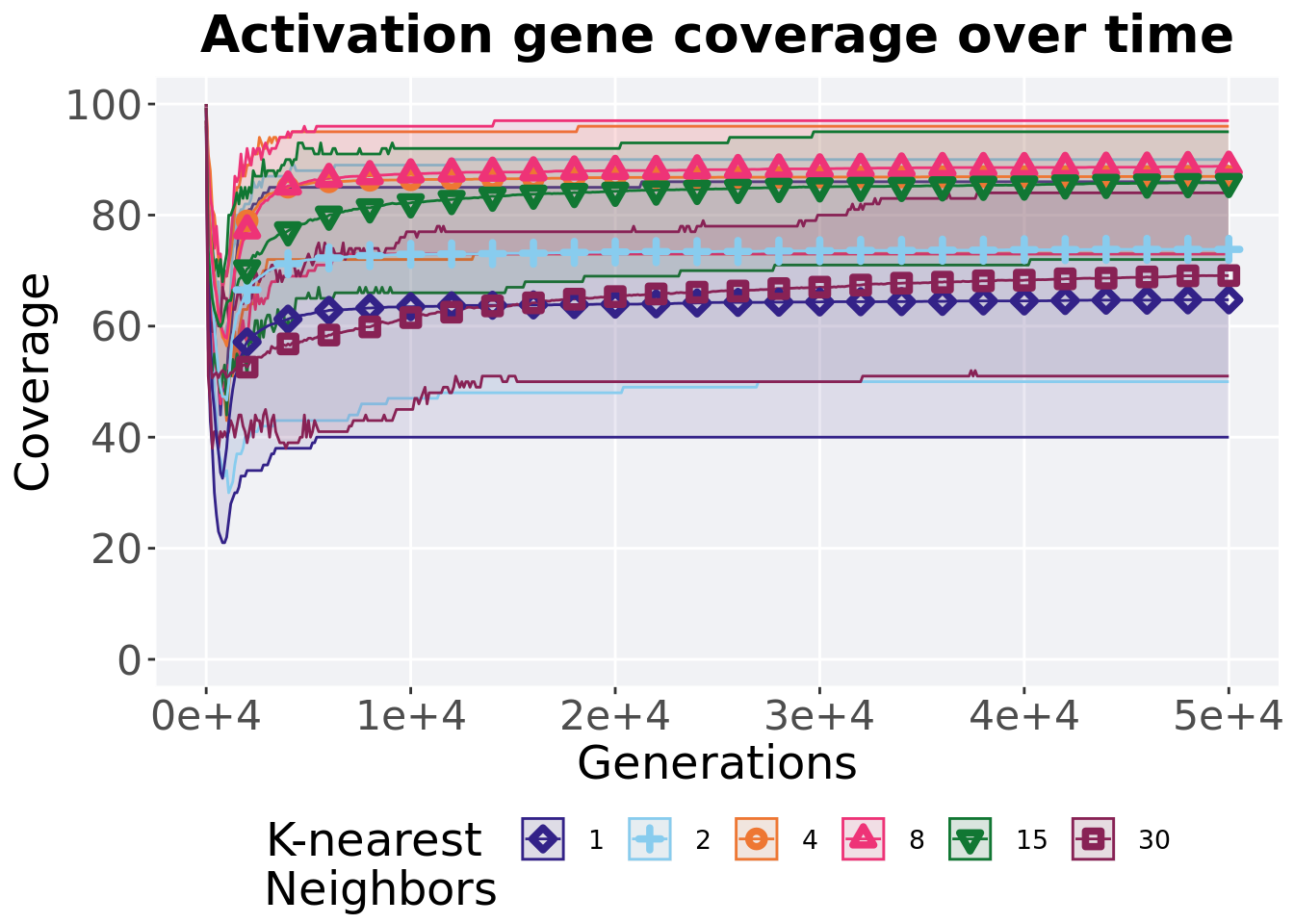
7.5.1 Activation gene coverage over time
Activation gene coverage in a population over time. Data points on the graph is the average activation gene coverage across 50 replicates every 2000 generations. Shading comes from the best and worse coverage across 50 replicates.
lines = filter(over_time_df, acro == 'mpe') %>%
group_by(K, gen) %>%
dplyr::summarise(
min = min(uni_str_pos),
mean = mean(uni_str_pos),
max = max(uni_str_pos)
)## `summarise()` has grouped output by 'K'. You can override using the `.groups`
## argument.ggplot(lines, aes(x=gen, y=mean, group = K, fill = K, color = K, shape = K)) +
geom_ribbon(aes(ymin = min, ymax = max), alpha = 0.1) +
geom_line(size = 0.5) +
geom_point(data = filter(lines, gen %% 2000 == 0 & gen != 0), size = 1.5, stroke = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Coverage",
limits=c(0, 100),
breaks=seq(0,100, 20),
labels=c("0", "20", "40", "60", "80", "100")
) +
scale_x_continuous(
name="Generations",
limits=c(0, 50000),
breaks=c(0, 10000, 20000, 30000, 40000, 50000),
labels=c("0e+4", "1e+4", "2e+4", "3e+4", "4e+4", "5e+4")
) +
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette) +
scale_fill_manual(values = cb_palette) +
ggtitle('Activation gene coverage over time')+
p_theme +
guides(
shape=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
color=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
fill=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors')
)
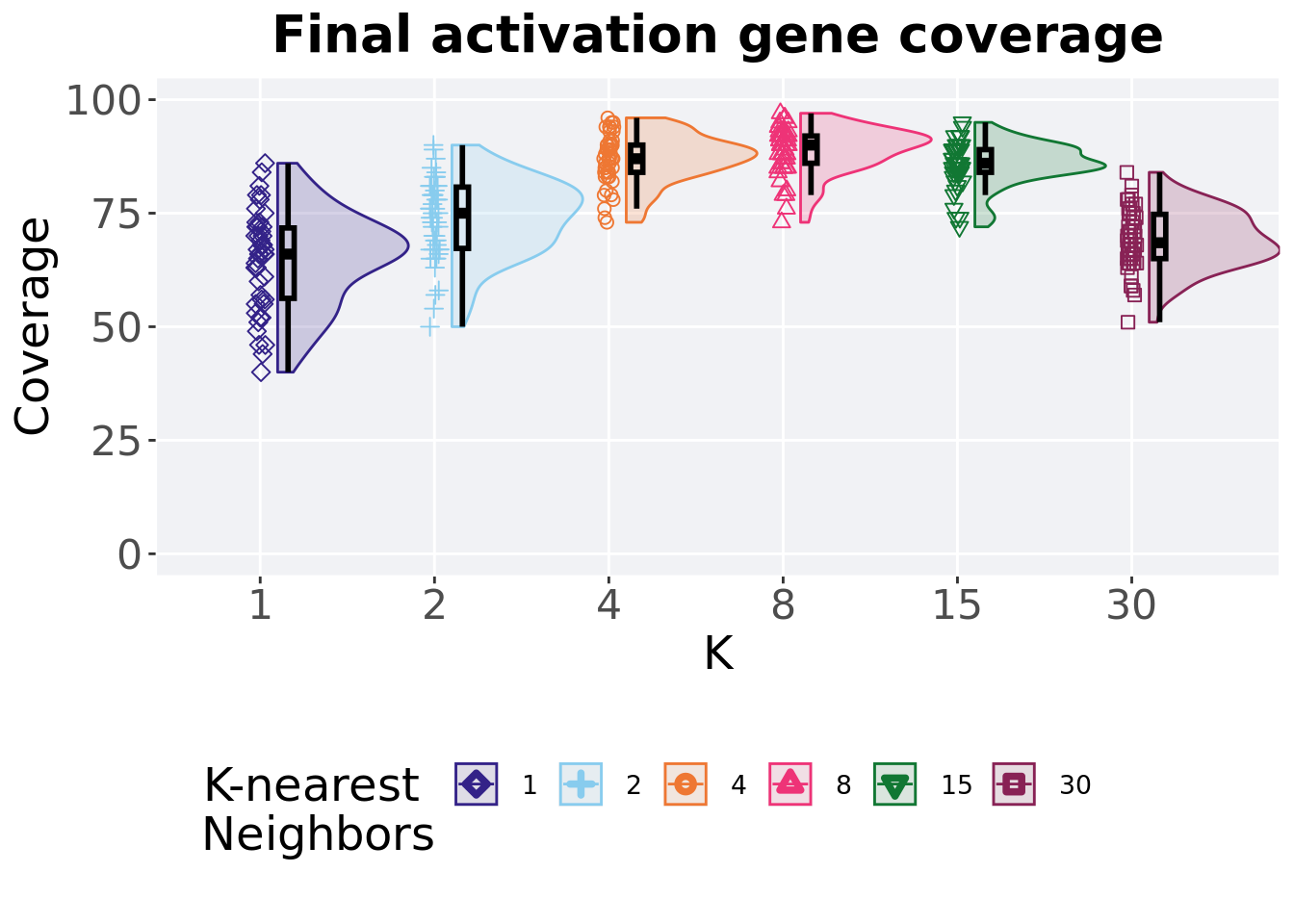
7.5.2 Final activation gene coverage
Activation gene coverage found in the final population at 50,000 generations.
plot = filter(over_time_df, gen == 50000 & acro == 'mpe') %>%
ggplot(., aes(x = K, y = uni_str_pos, color = K, fill = K, shape = K)) +
geom_flat_violin(position = position_nudge(x = .1, y = 0), scale = 'width', alpha = 0.2, width = 1.5) +
geom_boxplot(color = 'black', width = .07, outlier.shape = NA, alpha = 0.0, size = 1.0, position = position_nudge(x = .16, y = 0)) +
geom_point(position = position_jitter(width = 0.03, height = 0.02), size = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Coverage",
limits=c(0, 100)
) +
scale_x_discrete(
name="K"
)+
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette, ) +
scale_fill_manual(values = cb_palette) +
ggtitle('Final activation gene coverage')+
p_theme + theme(legend.title=element_blank())
plot_grid(
plot +
theme(legend.position="none"),
legend,
nrow=2,
rel_heights = c(3,1)
)
7.5.2.1 Stats
Summary statistics for activation gene coverage found in the final population at 50,000 generations.
act_coverage = filter(over_time_df, gen == 50000 & acro == 'mpe')
act_coverage$K = factor(act_coverage$K, levels = c('15','8','4','2','30','1'))
act_coverage %>%
group_by(K) %>%
dplyr::summarise(
count = n(),
na_cnt = sum(is.na(uni_str_pos)),
min = min(uni_str_pos, na.rm = TRUE),
median = median(uni_str_pos, na.rm = TRUE),
mean = mean(uni_str_pos, na.rm = TRUE),
max = max(uni_str_pos, na.rm = TRUE),
IQR = IQR(uni_str_pos, na.rm = TRUE)
)## # A tibble: 6 x 8
## K count na_cnt min median mean max IQR
## <fct> <int> <int> <int> <dbl> <dbl> <int> <dbl>
## 1 15 50 0 72 86 85.9 95 5
## 2 8 50 0 73 90 88.8 97 6
## 3 4 50 0 73 87 87.0 96 6
## 4 2 50 0 50 75 73.8 90 13.5
## 5 30 50 0 51 68.5 69.1 84 9.75
## 6 1 50 0 40 66 64.7 86 15.5Kruskal–Wallis test illustrates evidence of statistical differences.
##
## Kruskal-Wallis rank sum test
##
## data: uni_str_pos by K
## Kruskal-Wallis chi-squared = 199.94, df = 5, p-value < 2.2e-16Results for post-hoc Wilcoxon rank-sum test with a Bonferroni correction.
pairwise.wilcox.test(x = act_coverage$uni_str_pos, g = act_coverage$K, p.adjust.method = "bonferroni",
paired = FALSE, conf.int = FALSE, alternative = 't')##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: act_coverage$uni_str_pos and act_coverage$K
##
## 15 8 4 2 30
## 8 0.01842 - - - -
## 4 1.00000 0.77036 - - -
## 2 1.1e-10 5.5e-13 3.4e-11 - -
## 30 4.3e-15 6.8e-16 2.4e-15 0.02626 -
## 1 5.0e-15 8.6e-16 2.8e-15 0.00031 0.65316
##
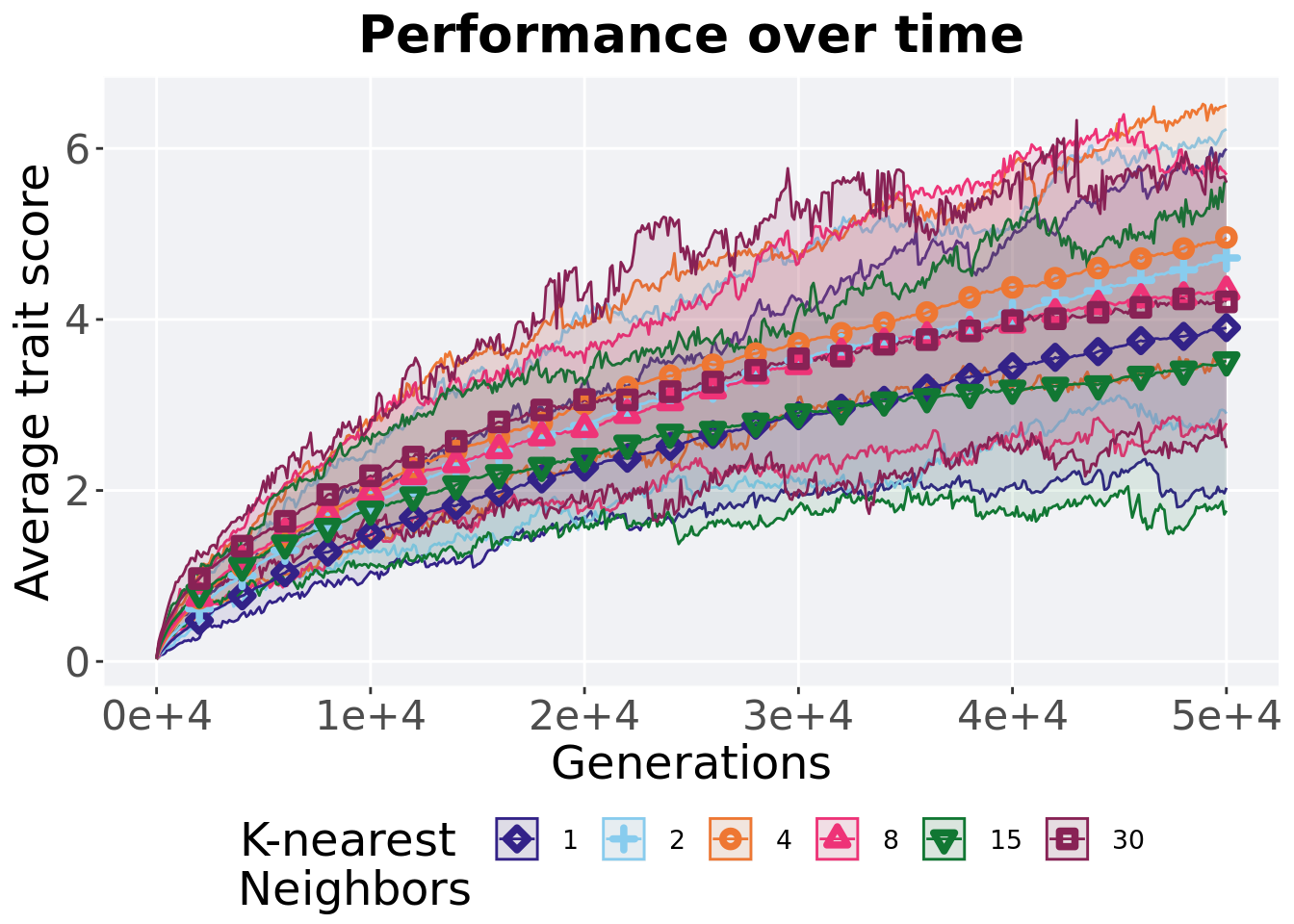
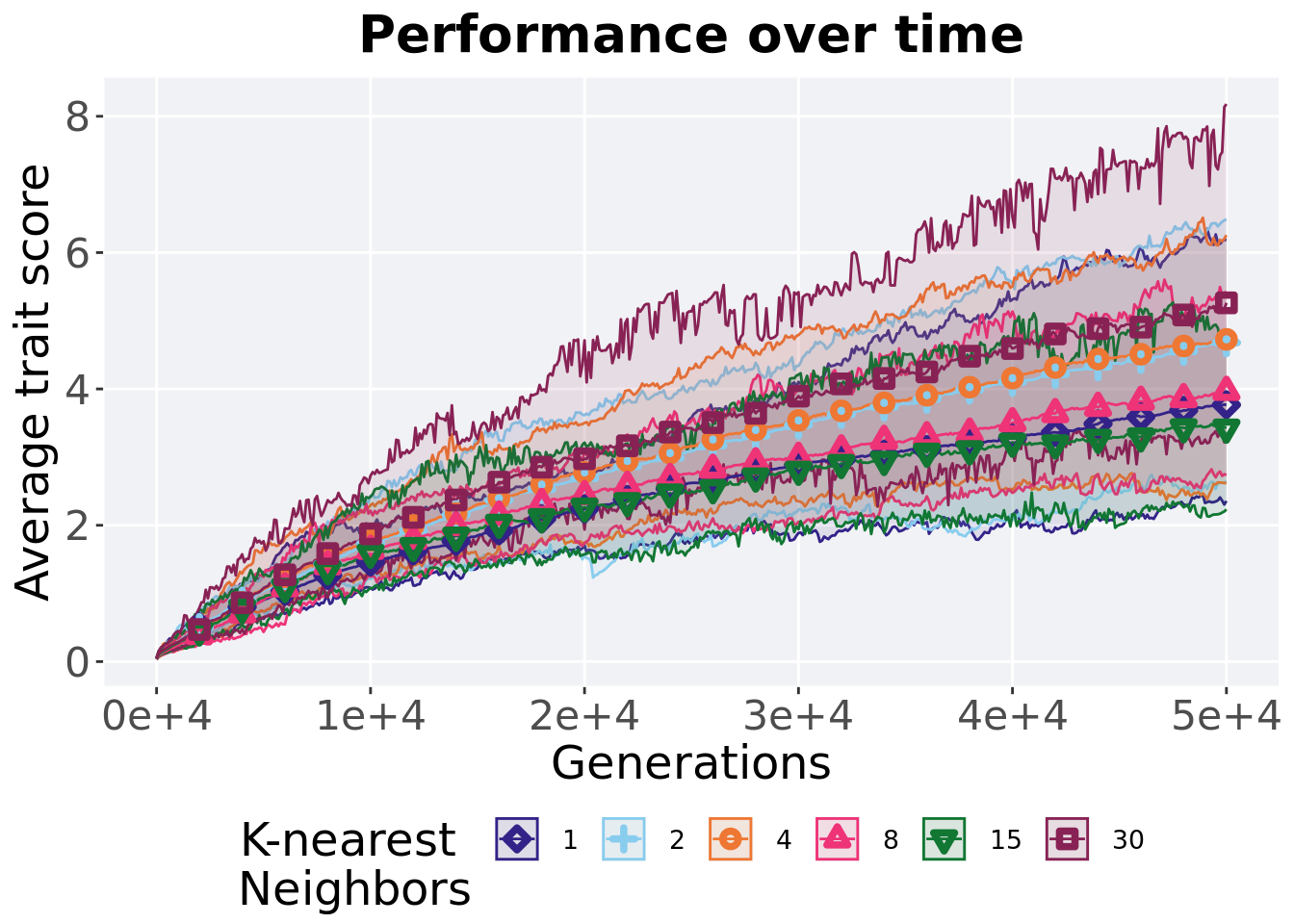
## P value adjustment method: bonferroni7.5.3 Performance over time
Best performance in a population over time. Data points on the graph is the average performance across 50 replicates every 2000 generations. Shading comes from the best and worse performance across 50 replicates.
lines = filter(over_time_df, acro == 'mpe') %>%
group_by(K, gen) %>%
dplyr::summarise(
min = min(pop_fit_max) / DIMENSIONALITY,
mean = mean(pop_fit_max) / DIMENSIONALITY,
max = max(pop_fit_max) / DIMENSIONALITY
)## `summarise()` has grouped output by 'K'. You can override using the `.groups`
## argument.ggplot(lines, aes(x=gen, y=mean, group = K, fill = K, color = K, shape = K)) +
geom_ribbon(aes(ymin = min, ymax = max), alpha = 0.1) +
geom_line(size = 0.5) +
geom_point(data = filter(lines, gen %% 2000 == 0 & gen != 0), size = 1.5, stroke = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Average trait score"
) +
scale_x_continuous(
name="Generations",
limits=c(0, 50000),
breaks=c(0, 10000, 20000, 30000, 40000, 50000),
labels=c("0e+4", "1e+4", "2e+4", "3e+4", "4e+4", "5e+4")
) +
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette) +
scale_fill_manual(values = cb_palette) +
ggtitle('Performance over time')+
p_theme +
guides(
shape=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
color=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors'),
fill=guide_legend(nrow=1, title.position = "left", title = 'K-nearest \nNeighbors')
)
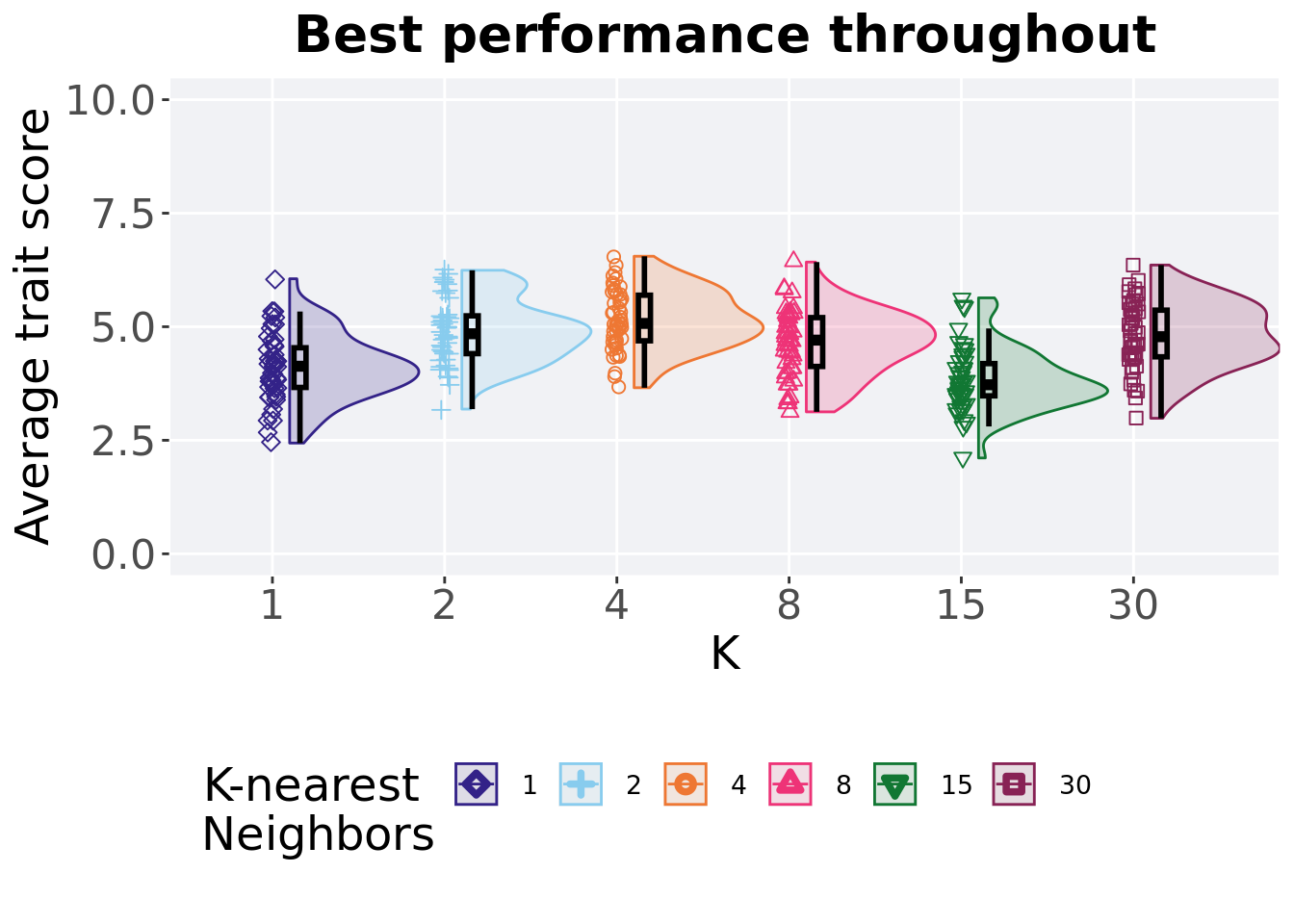
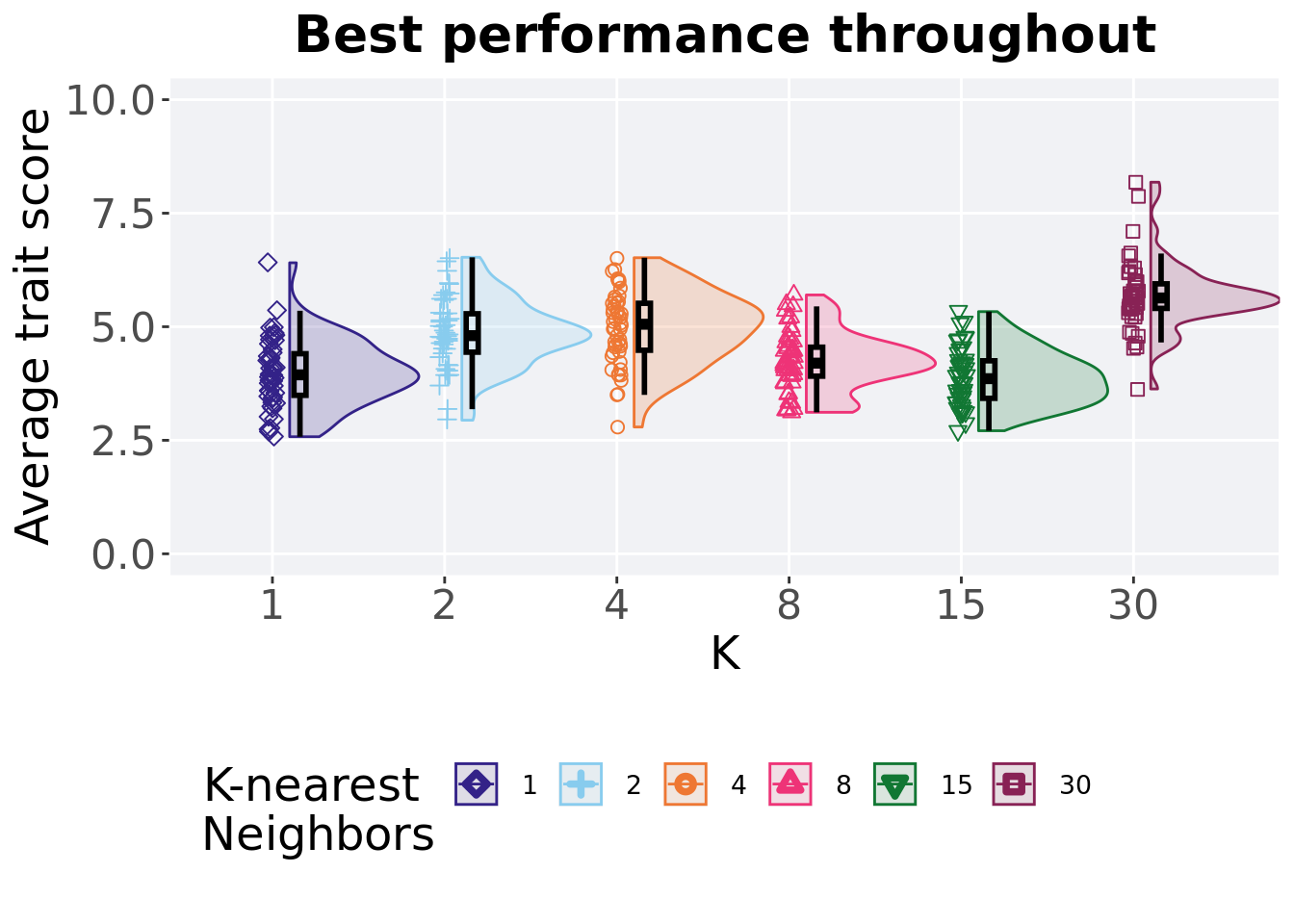
7.5.4 Best performance throughout
Best performance reached throughout 50,000 generations in a population.
plot = filter(best_df, var == 'pop_fit_max' & acro == 'mpe') %>%
ggplot(., aes(x = K, y = val / DIMENSIONALITY, color = K, fill = K, shape = K)) +
geom_flat_violin(position = position_nudge(x = .1, y = 0), scale = 'width', alpha = 0.2, width = 1.5) +
geom_boxplot(color = 'black', width = .07, outlier.shape = NA, alpha = 0.0, size = 1.0, position = position_nudge(x = .16, y = 0)) +
geom_point(position = position_jitter(width = 0.03, height = 0.02), size = 2.0, alpha = 1.0) +
scale_y_continuous(
name="Average trait score",
limits=c(0, 10)
) +
scale_x_discrete(
name="K"
)+
scale_shape_manual(values=SHAPE)+
scale_colour_manual(values = cb_palette, ) +
scale_fill_manual(values = cb_palette) +
ggtitle('Best performance throughout')+
p_theme + theme(legend.title=element_blank())
plot_grid(
plot +
theme(legend.position="none"),
legend,
nrow=2,
rel_heights = c(3,1)
)
7.5.4.1 Stats
Summary statistics for the best performance.
performance = filter(best_df, var == 'pop_fit_max' & acro == 'mpe')
performance$K = factor(performance$K, levels = c('30','4','2','8','1','15'))
performance %>%
group_by(K) %>%
dplyr::summarise(
count = n(),
na_cnt = sum(is.na(val)),
min = min(val / DIMENSIONALITY, na.rm = TRUE),
median = median(val / DIMENSIONALITY, na.rm = TRUE),
mean = mean(val / DIMENSIONALITY, na.rm = TRUE),
max = max(val / DIMENSIONALITY, na.rm = TRUE),
IQR = IQR(val / DIMENSIONALITY, na.rm = TRUE)
)## # A tibble: 6 x 8
## K count na_cnt min median mean max IQR
## <fct> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 30 50 0 3.63 5.63 5.68 8.18 0.541
## 2 4 50 0 2.79 5.06 4.97 6.52 1.03
## 3 2 50 0 2.94 4.80 4.86 6.53 0.846
## 4 8 50 0 3.12 4.20 4.24 5.70 0.638
## 5 1 50 0 2.58 3.94 3.98 6.41 0.916
## 6 15 50 0 2.71 3.86 3.88 5.33 0.826Kruskal–Wallis test illustrates evidence of statistical differences.
##
## Kruskal-Wallis rank sum test
##
## data: val by K
## Kruskal-Wallis chi-squared = 134.32, df = 5, p-value < 2.2e-16Results for post-hoc Wilcoxon rank-sum test with a Bonferroni correction.
pairwise.wilcox.test(x = performance$val, g = performance$K, p.adjust.method = "bonferroni",
paired = FALSE, conf.int = FALSE, alternative = 't')##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: performance$val and performance$K
##
## 30 4 2 8 1
## 4 0.00029 - - - -
## 2 7.4e-06 1.00000 - - -
## 8 5.5e-13 0.00011 0.00062 - -
## 1 1.3e-13 6.0e-07 2.0e-06 0.82300 -
## 15 4.3e-15 2.1e-08 5.8e-08 0.10653 1.00000
##
## P value adjustment method: bonferroni