publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2023
-
 Beyond Benchmarks Suites: Engineering Diagnostic Tools to Characterize Selection SchemesJose Guadalupe HernandezMichigan State University, 2023
Beyond Benchmarks Suites: Engineering Diagnostic Tools to Characterize Selection SchemesJose Guadalupe HernandezMichigan State University, 2023@phdthesis{hernandez2023beyond, title = {Beyond Benchmarks Suites: Engineering Diagnostic Tools to Characterize Selection Schemes}, author = {Hernandez, Jose Guadalupe}, year = {2023}, school = {Michigan State University}, } - Phylogeny-informed fitness estimationAlexander Lalejini, Matthew Andres Moreno, Jose Guadalupe Hernandez, and Emily Dolson2023
@misc{lalejini2023phylogenyinformed, title = {Phylogeny-informed fitness estimation}, author = {Lalejini, Alexander and Moreno, Matthew Andres and Hernandez, Jose Guadalupe and Dolson, Emily}, year = {2023}, eprint = {2306.03970}, archiveprefix = {arXiv}, primaryclass = {cs.NE}, }

2022
-
 An Exploration of Exploration: Measuring the Ability of Lexicase Selection to Find Obscure Pathways to OptimalityJose Guadalupe Hernandez, Alexander Lalejini, and Charles Ofria2022
An Exploration of Exploration: Measuring the Ability of Lexicase Selection to Find Obscure Pathways to OptimalityJose Guadalupe Hernandez, Alexander Lalejini, and Charles Ofria2022Parent selection algorithms (selection schemes) steer populations through a problem’s search space, often trading off between exploitation and exploration. Understanding how selection schemes affect exploitation and exploration within a search space is crucial to tackling increasingly challenging problems. Here, we introduce an “exploration diagnostic” that diagnosesLexicase selectionLexicase selectionepsilon lexicase selectionLexicase selectiondown-sampled lexicase selectionLexicase selectioncohort lexicase selectionLexicase selectionnovelty lexicase selectionParent selection a selection scheme’s capacity for search space exploration. We use our exploration diagnostic to investigate the exploratory capacity of lexicase selection and several of its variants: epsilon lexicase, down-sampled lexicase, cohort lexicase, and novelty-lexicase. We verify that lexicase selection out-explores tournament selection, and we show that lexicase selection’s exploratory capacity can be sensitive to the ratio between population size and the number of test cases used for evaluating candidate solutions. Additionally, we find that relaxing lexicase’s elitism with epsilon lexicase can further improve exploration. Both down-sampling and cohort lexicase—two techniques for applying random subsampling to test cases—degrade lexicase’s exploratory capacity; however, we find that cohort partitioning better preserves lexicase’s exploratory capacity than down-sampling. Finally, we find evidence that novelty-lexicase’s addition of novelty test cases can degrade lexicase’s capacity for exploration. Overall, our findings provide hypotheses for further exploration and actionable insights and recommendations for using lexicase selection. Additionally, this work demonstrates the value of selection scheme diagnostics as a complement to more conventional benchmarking approaches to selection scheme analysis.
@inbook{Hernandez2022, author = {Hernandez, Jose Guadalupe and Lalejini, Alexander and Ofria, Charles}, editor = {Banzhaf, Wolfgang and Trujillo, Leonardo and Winkler, Stephan and Worzel, Bill}, title = {An Exploration of Exploration: Measuring the Ability of Lexicase Selection to Find Obscure Pathways to Optimality}, booktitle = {Genetic Programming Theory and Practice XVIII}, year = {2022}, publisher = {Springer Nature Singapore}, address = {Singapore}, pages = {83--107}, isbn = {978-981-16-8113-4}, doi = {10.1007/978-981-16-8113-4_5}, url = {https://doi.org/10.1007/978-981-16-8113-4_5}, } -
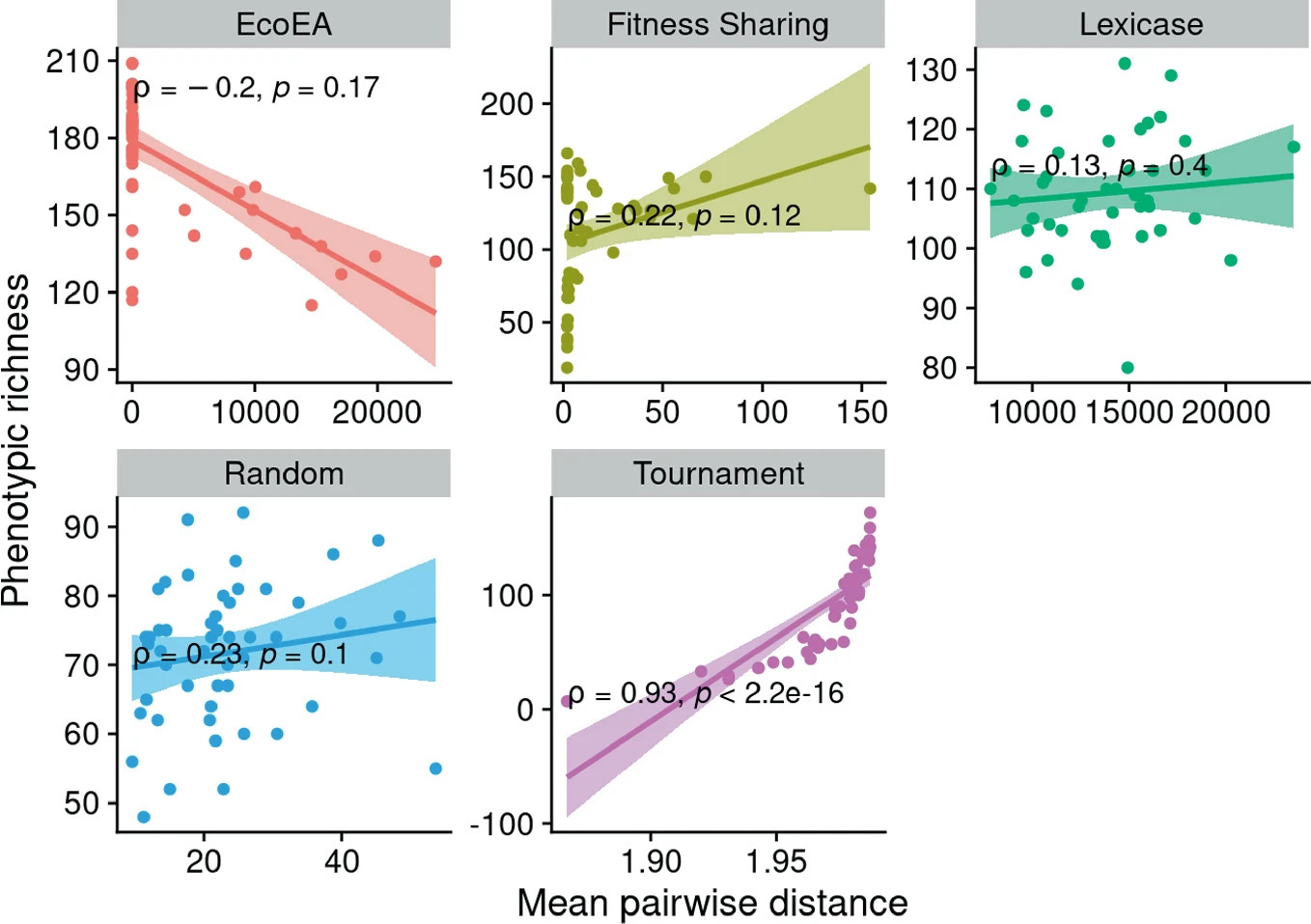 What Can Phylogenetic Metrics Tell us About Useful Diversity in Evolutionary Algorithms?Jose Guadalupe Hernandez, Alexander Lalejini, and Emily Dolson2022
What Can Phylogenetic Metrics Tell us About Useful Diversity in Evolutionary Algorithms?Jose Guadalupe Hernandez, Alexander Lalejini, and Emily Dolson2022It is generally accepted that “diversity” is associated with success in evolutionary algorithms. However, diversity is a broad concept that can be measured and defined in a multitude of ways. To date, most evolutionary computation research has measured diversity using the richness and/or evenness of a particular genotypic or phenotypic property. While these metrics are informative, we hypothesize that other diversity metrics are more strongly predictive of success. Phylogenetic diversity metrics are a class of metrics popularly used in biology, which take into account the evolutionary history of a population. Here, we investigate the extent to which (1) these metrics provide different information than those traditionally used in evolutionary computation, and (2) these metrics better predict the long-term success of a run of evolutionary computation. We find that, in most cases, phylogenetic metrics behave meaningfully differently from other diversity metrics. Moreover, our results suggest that phylogenetic diversity is indeed a better predictor of success.
@inbook{Hernandez2023, author = {Hernandez, Jose Guadalupe and Lalejini, Alexander and Dolson, Emily}, editor = {Banzhaf, Wolfgang and Trujillo, Leonardo and Winkler, Stephan and Worzel, Bill}, title = {What Can Phylogenetic Metrics Tell us About Useful Diversity in Evolutionary Algorithms?}, booktitle = {Genetic Programming Theory and Practice XVIII}, year = {2022}, publisher = {Springer Nature Singapore}, address = {Singapore}, pages = {63--82}, isbn = {978-981-16-8113-4}, doi = {10.1007/978-981-16-8113-4_4}, url = {https://doi.org/10.1007/978-981-16-8113-4_4}, } -
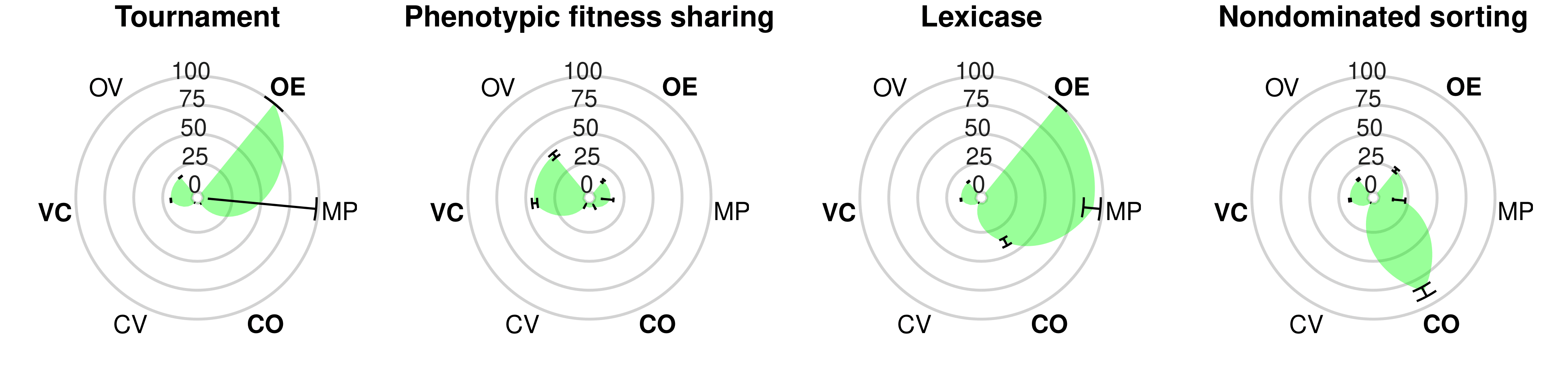 A suite of diagnostic metrics for characterizing selection schemesJose Guadalupe Hernandez, Alexander Lalejini, and Charles Ofria2022
A suite of diagnostic metrics for characterizing selection schemesJose Guadalupe Hernandez, Alexander Lalejini, and Charles Ofria2022Benchmark suites are crucial for assessing the performance of evolutionary algorithms, but the constituent problems are often too complex to provide clear intuition about an algorithm’s strengths and weaknesses. To address this gap, we introduce DOSSIER (“Diagnostic Overview of Selection Schemes In Evolutionary Runs”), a diagnostic suite initially composed of eight handcrafted metrics. These metrics are designed to empirically measure specific capacities for exploitation, exploration, and their interactions. We consider exploitation both with and without constraints, and we divide exploration into two aspects: diversity exploration (the ability to simultaneously explore multiple pathways) and valley-crossing exploration (the ability to cross wider and wider fitness valleys). We apply DOSSIER to six widely-used selection schemes: truncation, tournament, fitness sharing, lexicase, nondominated sorting, and novelty search. Our results confirm that simple schemes (\textite.g., tournament and truncation) emphasized exploitation. For more sophisticated schemes, however, our diagnostics revealed interesting dynamics. Lexicase selection performed moderately well across all diagnostics that did not incorporate valley crossing, but faltered dramatically whenever valleys were present, performing worse than even random search. Fitness sharing was the only scheme to effectively contend with valley crossing but it struggled with the other diagnostics. Our study underscores the utility of using diagnostics to gain nuanced insights into selection scheme characteristics, which can inform the design of new selection methods.
@misc{hernandez2022suite, title = {A suite of diagnostic metrics for characterizing selection schemes}, author = {Hernandez, Jose Guadalupe and Lalejini, Alexander and Ofria, Charles}, year = {2022}, eprint = {2204.13839}, archiveprefix = {arXiv}, primaryclass = {cs.NE}, } - Untangling Phylogenetic Diversity’s Role in Evolutionary Computation Using a Suite of Diagnostic Fitness LandscapesShakiba Shahbandegan, Jose Guadalupe Hernandez, Alexander Lalejini, and Emily DolsonIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2022
Diversity is associated with success in evolutionary algorithms. To date, diversity in evolutionary computation research has mostly been measured by counting the number of distinct candidate solutions in the population at a given time point. Here, we aim to investigate the value of phylogenetic diversity, which takes into account the evolutionary history of a population. To understand how informative phylogenetic diversity is, we run experiments on a set of diagnostic fitness landscapes under a range of different selection schemes. We find that phylogenetic diversity can be more predictive of future success than traditional diversity metrics under some conditions, particularly for fitness landscapes with a single, challenging-to-find global optimum. Our results suggest that phylogenetic diversity metrics should be more widely incorporated into research on diversity in evolutionary computation.
@inproceedings{10.1145/3520304.3534028, author = {Shahbandegan, Shakiba and Hernandez, Jose Guadalupe and Lalejini, Alexander and Dolson, Emily}, title = {Untangling Phylogenetic Diversity's Role in Evolutionary Computation Using a Suite of Diagnostic Fitness Landscapes}, year = {2022}, isbn = {9781450392686}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3520304.3534028}, doi = {10.1145/3520304.3534028}, booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference Companion}, pages = {2322–2325}, numpages = {4}, keywords = {transfer entropy, phylogenetic diversity, causality analysis, diversity}, location = {Boston, Massachusetts}, series = {GECCO '22}, } - Phylogenetic Diversity Predicts Future Success in Evolutionary ComputationJose Guadalupe Hernandez, Alexander Lalejini, and Emily DolsonIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2022
In our recent paper, "What can phylogenetic metrics tell us about useful diversity in evolutionary algorithms" [3], we explore the relationship between metrics of diversity based on phylogenetic topology and fitness. Our contribution is two-fold. First, we identify a technique for quantifying the relationship between diversity and fitness. Previous efforts to draw hard conclusions about this relationship had been stymied by the fact that these two properties are locked in a tight feedback loop. Second, we use this technique to assess the extent to which phylogenetic diversity leads to high-fitness solutions. We find that phylogenetic diversity is often more informative of future success in evolutionary algorithms than more commonly used diversity metrics, suggesting that is an underutilized tool in evolutionary computation research.
@inproceedings{10.1145/3520304.3534079, author = {Hernandez, Jose Guadalupe and Lalejini, Alexander and Dolson, Emily}, title = {Phylogenetic Diversity Predicts Future Success in Evolutionary Computation}, year = {2022}, isbn = {9781450392686}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3520304.3534079}, doi = {10.1145/3520304.3534079}, booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference Companion}, pages = {23–24}, numpages = {2}, keywords = {phylogenetic diversity, transfer entropy, causality analysis, diversity}, location = {Boston, Massachusetts}, series = {GECCO '22}, } - Measuring the Ability of Lexicase Selection to Find Obscure Pathways to OptimalityJose Guadalupe Hernandez, Alexander Lalejini, and Charles OfriaIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2022
This Hot-off-the-Press paper summarizes our recently published work, "An Exploration of Exploration: Measuring the Ability of Lexicase Selection to Find Obscure Pathways to Optimality," published as a chapter in Genetic Programming Theory and Practice XVIII [3]. In evolutionary search, selection schemes drive populations through a problem’s search space, often trading off exploitation with exploration. Indeed, problem-solving success depends on how a selection scheme balances search space exploitation with exploration. In [3], we introduce an "exploration diagnostic" that measures a selection scheme’s ability to explore different pathways in a search space. We use our exploration diagnostic to investigate the exploratory capacity of lexicase selection and several of its variants: epsilon lexicase, down-sampled lexicase, cohort lexicase, and novelty lexicase. We verify that lexicase selection out-explores tournament selection, and we demonstrate that lexicase selection’s ability to explore a search space is sensitive to the ratio between population size and the number of test cases used for evaluating candidate solutions. We find that relaxing lexicase selection’s elitism with epsilon lexicase can further improve search space exploration. Additionally, we find that both down-sampled and cohort lexicase—two methods of applying random subsampling to test cases—substantially degrade lexicase’s exploratory capacity; however, cohort partitioning better preserves exploration than down-sampling. Finally, we find evidence that the addition of novelty-based test cases can degrade lexicase selection’s exploratory capacity.
@inproceedings{10.1145/3520304.3534061, author = {Hernandez, Jose Guadalupe and Lalejini, Alexander and Ofria, Charles}, title = {Measuring the Ability of Lexicase Selection to Find Obscure Pathways to Optimality}, year = {2022}, isbn = {9781450392686}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3520304.3534061}, doi = {10.1145/3520304.3534061}, booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference Companion}, pages = {21–22}, numpages = {2}, keywords = {selection schemes, lexicase selection, fitness landscapes, diagnostics}, location = {Boston, Massachusetts}, series = {GECCO '22}, }



2020
-
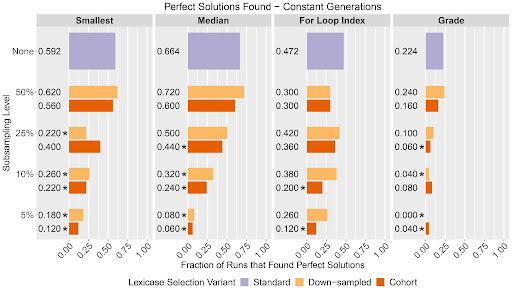 Characterizing the Effects of Random Subsampling on Lexicase SelectionAustin J. Ferguson, Jose Guadalupe Hernandez, Daniel Junghans, Alexander Lalejini, Emily Dolson, and Charles Ofria2020
Characterizing the Effects of Random Subsampling on Lexicase SelectionAustin J. Ferguson, Jose Guadalupe Hernandez, Daniel Junghans, Alexander Lalejini, Emily Dolson, and Charles Ofria2020Lexicase selection is a proven parent-selection algorithm designed for genetic programming problems, especially for uncompromising test-based problems where many distinct test cases must all be passed. Previous work has shown that random subsampling techniques can improve lexicase selection’s problem-solving success; here, we investigate why. We test two types of random subsampling lexicase variants: down-sampled lexicase, which uses a random subset of all training cases each generation; and cohort lexicase, which collects candidate solutions and training cases into small groups for testing, reshuffling those groups each generation. We show that both of these subsampling lexicase variants improve problem-solving success by facilitating deeper evolutionary searches; that is, they allow populations to evolve for more generations (relative to standard lexicase) given a fixed number of test-case evaluations. We also demonstrate that the subsampled variants require less computational effort to find solutions, even though subsampling hinders lexicase’s ability to preserve specialists. Contrary to our expectations, we did not find any evidence of systematic loss of phenotypic diversity maintenance due to subsampling, though we did find evidence that cohort lexicase is significantly better at preserving phylogenetic diversity than down-sampled lexicase.
@inbook{Ferguson2020, author = {Ferguson, Austin J. and Hernandez, Jose Guadalupe and Junghans, Daniel and Lalejini, Alexander and Dolson, Emily and Ofria, Charles}, editor = {Banzhaf, Wolfgang and Goodman, Erik and Sheneman, Leigh and Trujillo, Leonardo and Worzel, Bill}, title = {Characterizing the Effects of Random Subsampling on Lexicase Selection}, booktitle = {Genetic Programming Theory and Practice XVII}, year = {2020}, publisher = {Springer International Publishing}, address = {Cham}, pages = {1--23}, isbn = {978-3-030-39958-0}, doi = {10.1007/978-3-030-39958-0_1}, url = {https://doi.org/10.1007/978-3-030-39958-0_1}, }

2019
-
 Random Subsampling Improves Performance in Lexicase SelectionJose Guadalupe Hernandez, Alexander Lalejini, Emily Dolson, and Charles OfriaIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2019
Random Subsampling Improves Performance in Lexicase SelectionJose Guadalupe Hernandez, Alexander Lalejini, Emily Dolson, and Charles OfriaIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2019Lexicase selection has been proven highly successful for finding effective solutions to problems in genetic programming, especially for test-based problems where there are many distinct test cases that must all be passed. However, lexicase (as with most selection schemes) requires all prospective solutions to be evaluated against most test cases each generation, which can be computationally expensive. Here, we propose reducing the number of per-generation evaluations required by applying random subsampling: using a subset of test cases each generation (down-sampling) or by assigning test cases to subgroups of the population (cohort assignment). Tests are randomly reassigned each generation, and candidate solutions are only ever evaluated on test cases that they are assigned to, radically reducing the total number of evaluations needed while ensuring that each lineage eventually encounters all test cases. We tested these lexicase variants on five different program synthesis problems, across a range of down-sampling levels and cohort sizes. We demonstrate that these simple techniques to reduce the number of per-generation evaluations in lexicase can substantially improve overall performance for equivalent computational effort.
@inproceedings{10.1145/3319619.3326900, author = {Hernandez, Jose Guadalupe and Lalejini, Alexander and Dolson, Emily and Ofria, Charles}, title = {Random Subsampling Improves Performance in Lexicase Selection}, year = {2019}, isbn = {9781450367486}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3319619.3326900}, doi = {10.1145/3319619.3326900}, booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference Companion}, pages = {2028–2031}, numpages = {4}, keywords = {down-sampled lexicase, cohorts, program synthesis, cohort lexicase, parent selection, genetic programming, lexicase selection}, location = {Prague, Czech Republic}, series = {GECCO '19}, }
